教育部學術倫理電子報

生成式人工智慧(AI)快速的普及,為教育與研究場域帶來了明顯的影響,使高等教育與學術社群必須重新檢視知識產生與驗證的方式,本期主題文章提出「合情、合理、合法」的善用AI使用框架,此架構旨在協助學習者與研究者理解自身使用AI的需求,並在現行規範下維持必要的透明度與誠信原則。第二部分「中心新訊」回顧近期 AREE 更新內容,包括:上架 5 集 Podcast 廣播節目、新增 2 部情境影片、新增 2 主題之議題教材包、擴充領域辭典、上架 1 本教育電子書、擴充測驗題庫,新訊請點此查看。
學術誠信 2.0:AI 在教學研的轉化與回應
前言
自2022年11月底ChatGPT問世以來,生成式人工智慧(AI)已迅速成為全球矚目的AI服務,當時推出僅兩個月便擁有上億的使用者。生成式AI快速全面的普及,也為教育與研究場域帶來了明顯的衝擊,包括學生的學習、研究與寫作等,使高等教育與學術社群必須重新檢視知識產生與驗證的方式。
由於生成式AI模型具備流暢生成文本的能力,但常欠缺來源追蹤、推論可靠度與事實驗證機制,本文首先說明生成式AI的基本技術特性,包括其可能產生錯誤內容的原因,以及這些現象如何直接影響學術引用、推論與資料使用的正確性。接著,本文剖析生成式AI對學術誠信造成的關鍵挑戰。學術誠信的核心問題不單是禁用與否,而必須面對現今在AI趨勢下使用情境如何維持學術責任與研究產出的可驗證性。
基於上述現況,本文提出「合情、合理、合法」的善用AI使用框架,此架構旨在協助學習者與研究者理解自身使用AI的需求,並在現行規範下維持必要的透明度與誠信原則。本文期望此框架可供各級教育者、學習者與研究人員作為參考依據,使我們在AI技術成為日常工具的條件下,仍能持續進行有責任、具學術價值的知識實踐,讓學術社群在AI環境中維持誠信與可靠性的行動準則。
一、生成式AI的技術基礎與潛在倫理風險
(一)訓練資料與時效性
任何一個大型語言模型在開發過程中,必須收集大量資料,再利用這些資料進行模型訓練。這個訓練過程需要非常多的資料、清洗與運算時間,可能長達數週甚至數月,而且是在訓練開始前就已經收集完成。而這些訓練資料來源跨越一般網路文本(如Wikipedia、Common Crawl)、公開論壇與社群媒體內容,以及授權或合作取得的資料集。有些模型會加入特定領域的文獻,例如醫學(PubMed)、法律案例彙編或教科書等,但其比例因模型與公司政策而異,未必涵蓋完整的專業資料庫。
這些訓練資料在使用前會經過清理程序,包括移除明顯重複、垃圾資訊、格式錯誤與部分敏感內容。不過,由於資料規模龐大,資料清洗的品質控管多以啟發式規則與自動化工具為主,因此仍可能保留噪音或偏誤,並無法達到完全乾淨或無錯誤的狀態(Yu et al., 2024; Chen et al., 2024)。而模型在發布當下所具備的知識,其實是「訓練資料當時世界的樣子」,而不是引擎發布時的最新狀況。換言之,模型的內部知識是隨著訓練而被「凍結」起來的,無法像搜尋引擎一樣即時更新。故而當使用者詢問發生在訓練資料時點之後的事件,例如最新法規、當下最新事件或剛出現的術語,模型的反應可能會出現兩種情況:1.直接告訴你它不知道,因為資料時間不涵蓋。2.根據語言模式來生成推測答案,卻因此產生虛構或不正確的內容,或稱為AI幻覺。這些現象的發生是因為它只能依訓練時的資料來進行回答,無法確認資訊的真實性。因此,瞭解模型的資料時間範圍與每個模型發布的時間落差,是負責任使用AI的第一步。
(二)詞彙表與資料偏差
AI在理解與生成文本時,仰賴一個巨大的拼圖庫,也就是由詞元(token)構成的詞彙表。每個詞元是一塊拼圖,其分割的語言單位可能是單字、字根、子詞、標點或單一字母,並非人類理解的「單詞」。當使用者輸入一段文字,系統會將其切分為詞元,再根據詞彙表中的編碼轉換成對應向量值,以送入深度神經網路模型中進行處理。當模型生成回應時,會依據語言模式與上下文逐一預測下一個最有可能出現的詞元,這個過程會反覆進行,直到完整生成內容。生成式AI的詞彙可能涉及以下資料倫理問題:
若訓練資料本身含有偏見(性別、族群、國籍、階級等),詞元統計分布會放大既有偏見,使模型可能生成不公平或刻板化的內容。
若資料集中某些語言或文化的文本比例低,詞彙表與語言模式將反映這種不對稱,使模型在處理弱勢語言或文化內容時產生理解困難或失真。
由於詞彙表隨模型訓練有其時間限制,新興詞彙、科技術語或流行語無法即時納入,使模型面對最新語言使用時的表現受限。
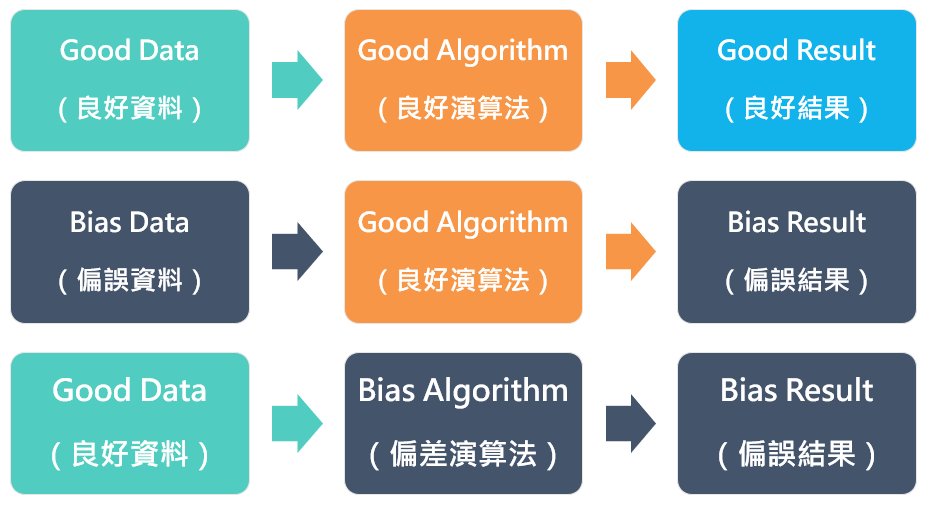
在理解生成式AI的偏差來源時,我們常會從「資料」與「演算法」兩個方向來看它的產出品質。因為生成式AI是透過大量資料學習語言規律,再由演算法決定如何組合這些規律,所以這兩者的組合方式,會直接影響模型給出的內容是否可靠。以下三種情境,說明AI可能呈現的不同結果(如圖1)。
情況一:資料品質良好,模型設計也合宜。是指當訓練資料具有多樣性、可信度高、噪音較少,而且模型在設計時兼顧語言特性、數值穩定與風險控管機制時,AI生成的內容通常較為合理。這並不表示模型絕對正確,而是它的學習素材和學習方式都比較健全,因此在面對一般知識、基礎科學或常見語言使用情境時,其輸出較接近人類可接受的品質。
情況二:資料本身有偏差,演算法沒有問題。這類問題在AI倫理中被討論最頻繁,也最具代表性。若訓練資料中某些族群語料比例過低、網路文本充滿刻板印象,或某些語言與文化的呈現不對稱,即使演算法設計得再良好,模型仍可能生成帶有偏差的回應。這是因為模型的語言模式,直接反映資料中的分布與偏見。結果會導致AI在回應中不自覺強化主流文化觀點,忽略弱勢語言,甚至重複社會中的歧視語句。此情況提醒我們:偏差常不是演算法造成的,而是世界本身的資料就不均衡。
情況三:資料良好,但演算法的設計帶來偏差。這種偏差通常源自技術選擇,而不是資料本身。例如:詞元設計方式無法良好處理某些語言,使得模型在面對這些語言時表現不佳;或者在生成策略上,演算法傾向挑選最常見的回應,使較少見的文化表達被自動忽略。此外,風險控管與內容審查機制若設計得太嚴或太鬆,也可能影響AI的回應方向。即便資料來源多元完整,若模型的內部機制無法有效利用這些資料,產出的內容依然可能偏向特定表述方式。
美國白宮前技術長Megan Smith(The White House, 2016)指出,資料與演算法系統的偏差往往源自資料缺漏、變項選取不足或模型邏輯設計的不周延。即便演算法本身運作正常,只要資料來源過度單一,產生的模式仍可能無法反映真實社會,甚至將特定價值觀或刻板印象固定化,從而忽略多元價值。
綜合來看,生成式AI的輸出結果,是「資料」與「演算法」共同作用的結果。資料偏差會讓模型學到不完整的世界樣貌;演算法偏差則會讓模型即使擁有良好資料,仍無法呈現公平多元的內容。正因如此,在教育與學術研究中,瞭解這兩種偏差的來源,是使用生成式AI時維持判斷力的重要基礎。
圖1 AI運作模式與生成結果
資料來源:作者自行整理。


